GEO优化做了一段时间以后,到底该看什么才算有效?
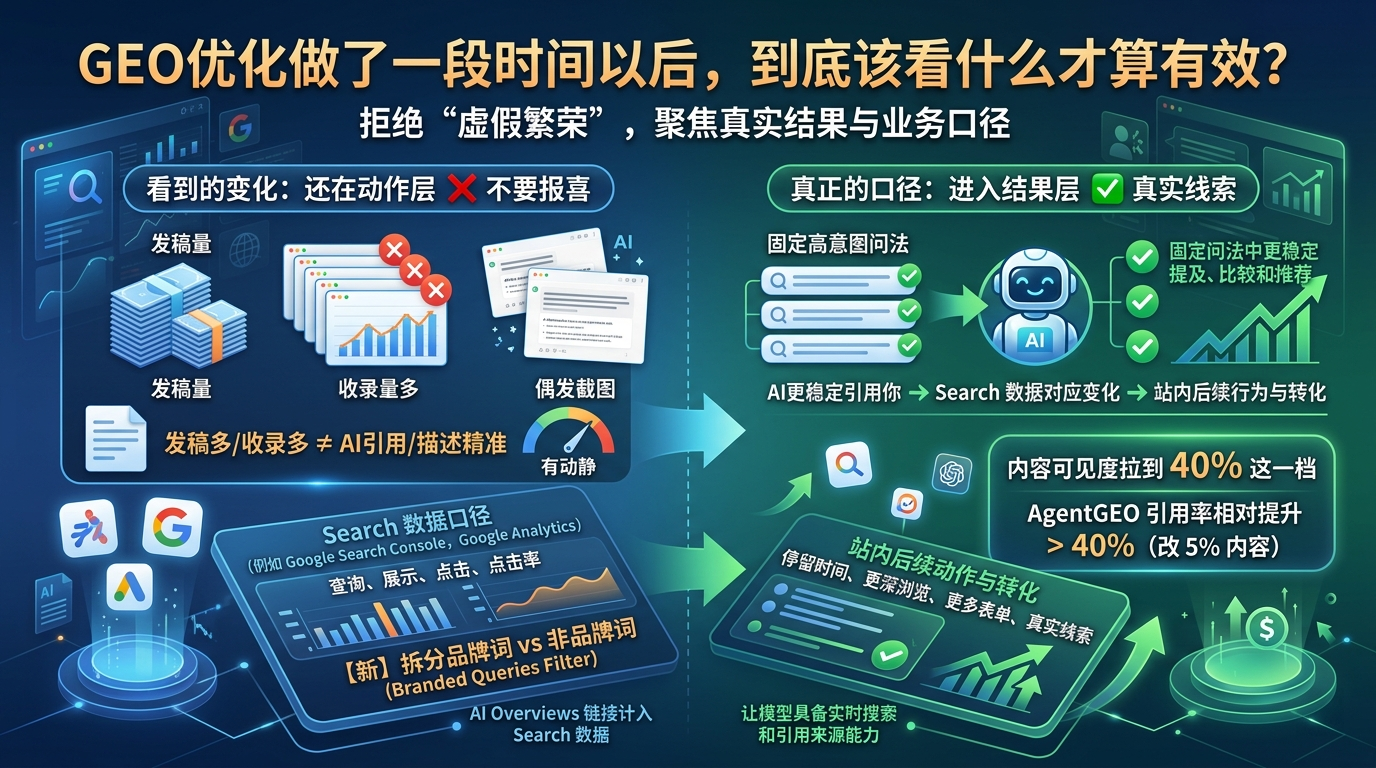
GEO优化做了一段时间,到底算不算开始有效,不要急着把“有动静”当成“有结果”。发稿量、收录量和偶发截图都能看,但不能直接拿来报喜。更稳的判断,是固定高意图问法里你是不是开始更稳定地被提到、被带进比较和推荐,再看这些变化能不能接到 Search 数据、站内行为和真实线索。
之所以要先把这两层拆开,是因为 GEO 真正改的,不是“本周又发了几篇”,而是 AI 在回答相关问题时,会不会更愿意拿你的公开信息来解释、比较和引用。GEO 论文给过一组很直观的结果:合适的优化策略,最高能把内容可见度拉到 40% 这一档。另一篇专门看 citation failures 的研究也给了同样的提醒:不用整站大改,只动少量关键内容,引用率就可能明显往上走。对复盘来说,这比“更新量有没有上去”离真正该看的结果层近得多。
哪些变化还不能直接算结果
下面这些变化可以看,但都不适合直接当“已经有效”的结论。
| 看到的变化 | 为什么还不能直接算结果 | 更稳的看法 |
|---|---|---|
| 发稿量比以前多了 | 这只能说明动作变多,不能说明 AI 已经开始用你 | 先回到固定高意图问法,看答案里有没有更稳定地带出你 |
| 页面收录和索引多了 | 这说明底座在补齐,但离进入答案层还隔着一段 | 看这些页面有没有开始支撑提及、比较和引用 |
| 平台里偶尔提到过一次 | 单次截图很容易碰巧出现,也容易被旧信息和错误描述干扰 | 连续看同一批问题,确认它是不是稳定出现,而且出现得更准 |
| 某几篇内容流量涨了 | 流量可能来自品牌词、热点或别的入口,不一定来自 GEO 起色 | 拆开品牌词和非品牌词,再看进站后的停留、回访和转化 |
很多团队常常卡在这里。因为前面三项都很容易汇报,也很容易让人先松一口气。可真正难的是把它们和“AI 有没有开始更愿意用你”分开看。只要这一步没分开,后面越复盘越像在数动作,不像在判断结果。
真正该先看的 4 个口径
先把下面这 4 项摆到前面。
| 先看什么 | 具体看法 | 为什么它排在前面 |
|---|---|---|
| 固定高意图问法 | 问题别反复换,看同一批定义题、比较题、推荐题里你有没有更稳定地出现 | 问法一旦乱换,前后就没法比 |
| 结果层变化 | 看是不是从“完全没有你”变成“会提到你”,再到“会带进比较和推荐” | 这是最接近 AI 真结果的位置 |
| 品牌词 / 非品牌词 | 用 Search Console 把品牌词和非品牌词拆开看,别把用户本来就认识你误当成 GEO 起色 | 这一步能防止自我安慰 |
| 站内后续动作 | 看点击后有没有更长停留、更深浏览、更多表单、咨询或指名提问 | 真正有效,最后要能接到真实判断和线索 |
Google Search Central 在 AI features and your website 里已经把一条关键口径写明了:AI Overviews 和 AI Mode 里的链接,会计进整体 Search 数据。你不是只能在模型里截图,本来就该回到 Search 数据里看前后变化。
它在《Using Search Console and Google Analytics data for SEO》里又把分工拆得很清楚:Search Console 更适合看用户点进来之前的查询、展示、点击和点击率,Google Analytics 更适合看点进来以后发生了什么,比如停留、回访和转化。2025 年 11 月,Search Console 又上线了 branded queries filter,品牌词和非品牌词终于可以分开看。这一层一拆开,很多看起来“有起色”的数据,立刻就会露出本来面目。
如果把这一组公开口径连起来看,它本身就很像一段可执行的案例结果。Google 官方的意思不是“AI 结果自成一套看不见的数据”,而是用户会在 AI 结果里看到正常链接,这些点击会出现在整体 Search 数据里,品牌词和非品牌词也能拆开看。对 GEO 复盘来说,你终于能把“模型里有没有开始带出你”和“站内有没有接到真实点击与转化”接到一起。
为什么这几项比发稿量和收录量更值钱
因为 GEO 讲到底不是在比谁更勤快,而是在比谁更早开始影响答案怎么组织。
GEO 论文里那组 40% 可见度结果,和 AgentGEO 里那组“改 5% 内容、citation rate 相对提升超过 40%”的结果,都在说明同一件事:真正先动的,不是“页面数”,而是“AI 会不会更愿意看见你、用你、引用你”。如果一轮 GEO 做了两个月,还是只能报“发了多少、收了多少”,那这轮最多算动作有了,还不能算结果站住。
中文场景也一样。腾讯云的联网搜索 API 页面,把这条链路说得很直接:它是以互联网全网公开资源为基础的搜索增强接口,目标是让模型具备实时搜索、精准问答和引用来源能力。放到 GEO 复盘里,人话就是,你更该盯的是固定问法里有没有开始更稳定地被带出来、被点进去,而不是内容发得热不热闹。
所以真正有效,通常不是一张截图,而是一个顺序:固定问法里更常出现你,描述更准了;Search 数据里开始能看见对应变化;进站以后,用户更愿意继续看、继续问、继续留线索。这个顺序一旦连起来,才更像“开始有效”。只要还停在前两步之前,就别忙着报喜。
继续往下问,通常会落在这三个问题上
偶尔被提到一次,为什么还不能直接算有效?
因为单次提及太容易碰运气,也太容易被错误描述、旧信息和一次性问法干扰。真正更稳的判断,是同一批高意图问题里,你是不是开始稳定出现,而且出现的位置和说法都更贴近你想要的结果。
发稿量和收录量到底还能不能看?
能看,但更适合放在“动作有没有做起来”这一层。它们能解释底座有没有在补,解释不了答案层是不是开始站住。只要把它们抬成第一结论,复盘就很容易变成数动作。
做了两个月没感觉,最该先排查什么?
不用上来就补更多内容,先把 3 件事查清:高意图问法是不是定住了;结果层有没有分开看“知道你、提到你、进入比较和推荐”;品牌词和非品牌词、进站后的停留和转化有没有拆开看。前面这几项没立住,后面加量通常只会把噪音一起放大。
参考依据
- arXiv: GEO: Generative Engine Optimization
- arXiv: Diagnosing and Repairing Citation Failures in Generative Engine Optimization
- Google Search Central: AI features and your website
- Google Search Central: Using Search Console and Google Analytics data for SEO
- Google Search Central Blog: Introducing the branded queries filter in Search Console
- 腾讯云:联网搜索 API